Pandas kullanıyordum. Konuyla ilgili tavsiye edebileceğiniz kaynak var mı?
Datanın tamamını göremediğim için çıkarım yapamıyorum. Null değerleri zaten pandas ile düzeltmeniz lazım. Bu kadar büyük veri için bu analizi nasıl yapabilirim sorusunun cevabı scikit-learn.
1. Pandas ile null verileri atamanız ya da silmeniz gerekiyor. Yöntemlerini açıklıyacağım.
Tüm yöntemler burada mevcut :
https://medium.com/@ayeshasidhikha18...s-a90bb02e2bd9
- Tüm properyler için aynı yöntemi kullanmayın.
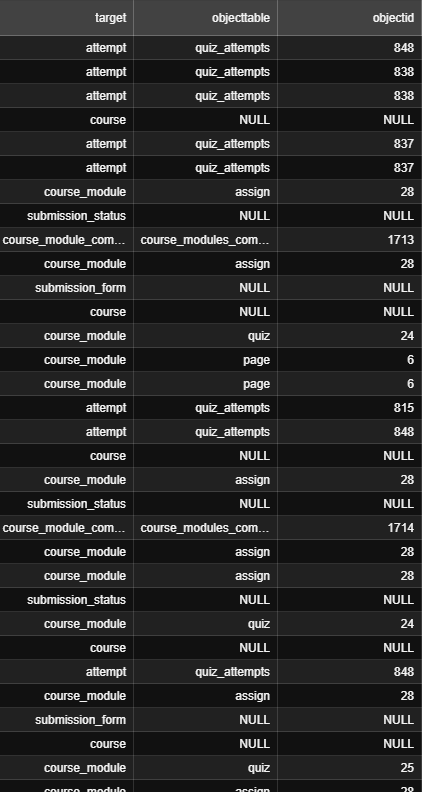
* Mesela dediğim gibi idnumber gibi bir durum varsa bu unique bir durumdan kaynaklanıyordur. Örneğin attempt için objectid değerinde null varsa atanan değeri 800lü olan bir değere yuvarlayın. Eğer O property için öncesinde hiç objectid değeri girilmemişse kendiniz değer belirleyin. fillna() kullanmanız gerekir.
*
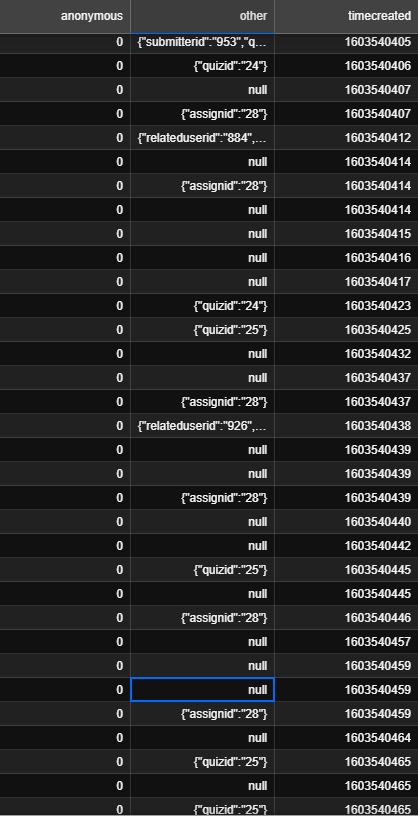
bfill(backward filling) - ffill(forward filling) aynı target propertysinde olan nulllar için kullanabilirsin. (Görebildiğim kısıtlı verilerin sonucunda, burada target ana veri (diğer verilerin tipini belirleyen property gibi duruyor.))
2. Ardından scikit-learn ile işlemeyi yapıp sonuçlara göre hangi yöntemi daha mantıklı sonuç verdiğine bakmanız gerekiyor.