
https://www.hepsiburada.com/bayan-gu...c-60000121#i13
Bunları çekmeye çalışıyorum.
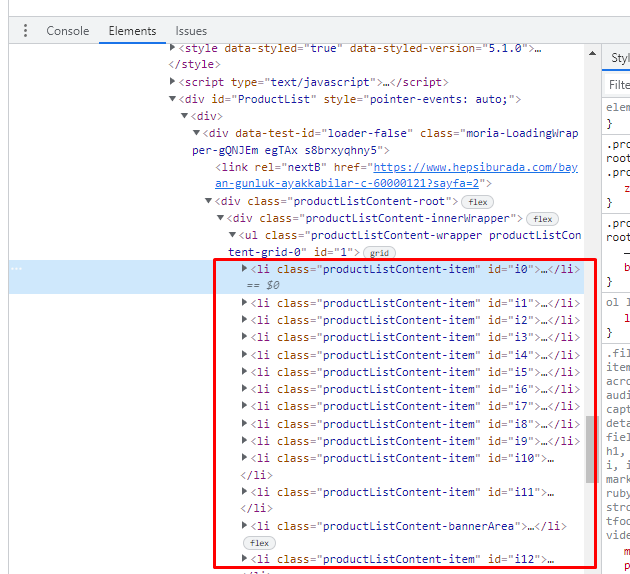
4. satırda hata var
soup = BeautifulSoup(r.content,"lxml")
st1 =soup.find("div",attrs={"class":"productListContent-innerWrapper"})
st2 = st1.find("ul",attrs={"class":"productListContent-wrapper productListContent-grid-0"})
st3 = st2.find_all("li",attrs={"class":"productListContent-item"}) # Hata aldığım satır
liste = []
for bilgi in st3:
linksonu=bilgi.a.get("href")
linkbasi="https://www.hepsiburada.com"
sonlink =link_basi+link_sonu
print(sonlink)
r1 = requests.get(sonlink,headers=headers)
soup1 = BeautifulSoup(r1.content,"lxml")
yeni_fiyat=soup1.find("span",attrs={"itemprop":"price"}).text.strip().replace("\n","")
print(yeni_fiyat)
Orjinal_Fiyat=soup1.find("del",attrs={"id":"originalPrice"}).text
print(Orjinal_Fiyat)
indirim_yuzdesi=soup1.find("span",attrs={"id":"product-discount-rate"}).text.strip().replace("\n\r\n "," ")
print(indirim_yuzdesi)
puani = soup1.find("span",attrs={"class":"rating-star"}).text.strip()
print(puani)
degerlendirme_sayisi = soup1.find("div",attrs={"id":"comments-container"}).text.strip()
print(degerlendirme_sayisi)
urun_adi = soup1.find("h1",attrs={"itemprop":"name"}).text.strip()
print(urun_adi)
markasi = soup1.find("span",attrs={"class":"brand-name"}).text.strip()
print(markasi)
urun_resmi = soup1.img.get("src")
print(urun_resmi)
ayakkabi_numaralari = soup1.find_all("div",attrs={"data-bind":"click: setActiveVariantContainer"})
ayakkabi_numara_liste = []
for numara in ayakkabi_numaralari:
a = numara.find("label",attrs={"class":"label white"}).text.strip()
ayakkabi_numara_liste.append(a)
print(ayakkabi_numara_liste)
liste.append([urun_adi,markasi,sonlink,urun_resmi,yeni_fiyat,Orjinal_Fiyat,indirim_yuzdesi,puani,degerlendirme_sayisi,ayakkabi_numara_liste])
listeedit sanırım kod sadece bir linki çekiyor <li> class'ındaki tüm linkleri almam lazım