
if ($kac == 100){
$url = 'https://www.google.com.tr/search?num=500&hl=tr&lr=&q='.$kelime.'&filter=0';
$v = file_get_contents_curl($url);
preg_match_all('/class="r"><a href=(.*?)sa/si',$v,$r);
foreach($r[1] as $tum){
$tt = str_replace('"/url?q=','',$tum);
$tt = str_replace('/&','',$tt);
$tt = str_replace('amp;','',$tt);
$tumu [] = $tt;
}bu kodlarla google arama sonuçlarını listeliyorum... Tabi kodların bir kısmı sadece bu.. şimdi sormak istediğim şu listelerken örneğin $kelime="google" olduğunu düşünelim yani google'da google kelimesini arıyorum fakat bunları sıralarken alt sayfalarınıda sıralamaya dahil ediyor. bunu bir resimle açıklamak istiyorum..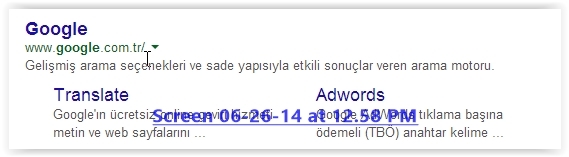
şimdi resimde gördüğünüz kısmı şöyle listeliyor.
1.google.com
2.translate olan yeri
3.adwords olan yeri listeliyo.
halbuki bu sadece bir site yani ;
1.google.com
2.sıradaki site olmalı
google.com'un alt bölümlerini listelememeli nasıl yapabilirim bunu..
preg_match_all kısmında değişiklik yapmam gerekiyor sanırım..
özellikle class="r" kısmında direk <h3> leri listelemesinden kaynaklanıyor gibi geliyo bunu nasıl değiştireyimki sadece ana siteleri listelesin..?






