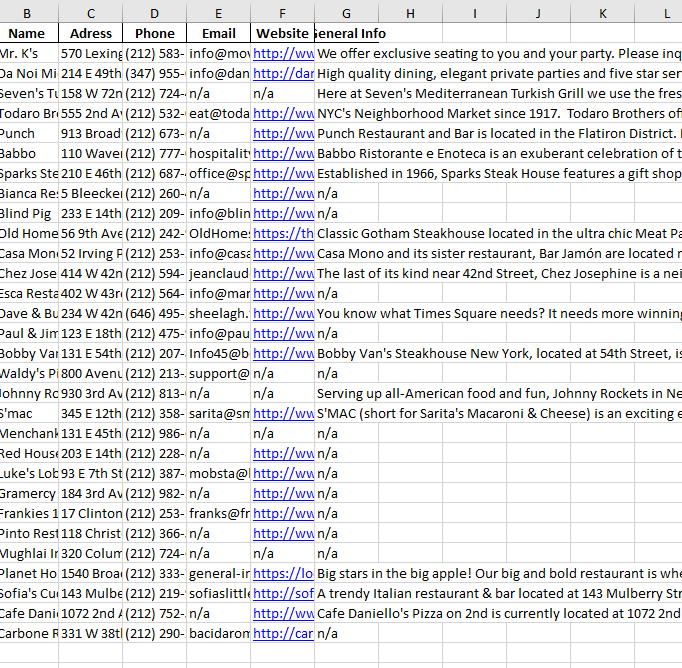
Demin bu her iki hatayıda çözdüm. Çözümümü sizinle paylaşıyorum.
Benden başka aynı hatayı alacak olanlar olursa bu şekilde çözüm bulabilirler
results = []
for link in urls:
response3 = requests.get(link,)
soup2 = BeautifulSoup(response3.content, "html.parser")
try:
names = soup2.find("h1").get_text().replace("\ufeffAdd to Favorites", "")
except:
names = "n/a"
try:
adresses = soup2.find("span",{"class":"address"}).get_text()
except:
adresses = "n/a"
try:
phones = soup2.find("a",{"class":"phone"}).get_text()
except:
phones = "n/a"
try:
emails = soup2.find("a", {"class":"email-business"}).get("href").replace("mailto:","")
except:
emails = "n/a"
try:
websites = soup2.find("a",{"class":"website-link"}).get("href")
except:
websites = "n/a"
try:
infos = soup2.find("dd", {"class":"general-info"}).get_text()
except:
infos = "n/a"
output = {"Name":names,
"Adress":adresses,
"Phone":phones,
"Email":emails,
"Website":websites,
"General Info":infos}
results.append(output)
yellowpages = pd.DataFrame(results)Sonuç