Selam hocalarım, aktif olan opanai api kullanıyorum fakat su gibi parayı emiyor namussuz.
Bunu optimize etmenin yolu var mı?
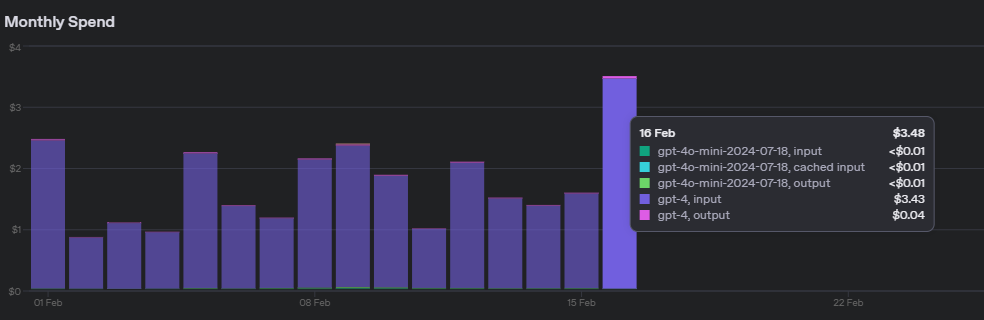
model olarak gpt-4o-mini kullanıyorum.
ve ek olarak
"role" => "system", "content" =>
kısmında çok fazla rolü mevcut ondan da etkileniyor olabilir mi bilmiyorum.
bir fikri olan var mı?
ChatGPT Api ücretini optimize etmek mümkün mü?
9
●270
- 16-02-2025, 22:14:01
- 16-02-2025, 22:18:14input değerini yani role ve promtları olabildiğince az olsun, cevaplar uzun geliyorsa output değerini kısmak için role den yönlendirme yapın.
- 16-02-2025, 22:24:17
- 16-02-2025, 22:26:08Ama sizin bakiyeyi arttıran şey gpt-4zNightLastTR adlı üyeden alıntı: mesajı görüntüle

Siz 4-o mini kullanmamışsınız pek fazla - 16-02-2025, 22:30:09işin garip tarafı tüm projeler 4-o miniVektorMedya adlı üyeden alıntı: mesajı görüntüle
- 16-02-2025, 22:30:55API kodunuzda hata var direkt gpt-4 kullanmışsınız hocam, o çok çok maliyetlizNightLastTR adlı üyeden alıntı: mesajı görüntüle
- 16-02-2025, 22:44:17file_put_contents ile hepsinin modellerini test edeceğimVektorMedya adlı üyeden alıntı: mesajı görüntüle
hiç kontrol etmedim ama bakarım teşekkür ederim.ernsaygin adlı üyeden alıntı: mesajı görüntüle